tl;dr: A mix of tabs and spaces for your indent will cause this problem. At least in Python 2.7.
I post this since the answers I see in Google/Stackoverflow all talk about scope, and I didn't have a scope issue. That's pretty much it. This usually happens when I paste some code in from an example online (like from Stackoverflow, which I do like most of the time), it comes in with spaces but I prefer to use tabs.
Thursday, November 19, 2015
Python local variable referenced before assignment
Sunday, November 15, 2015
Facebook, Paris, Beruit
A lot has been written about how Facebook activated its "Safety Check" feature for the recent Paris terrorist attack, but not for one the previous day in Beirut. There is some good commentary, from less well known sites to the bigger news sites to personal blogs.
So what are we left with?
Facebook is a part of the global media fabric as much as any other site, they not only act as gatekeepers for news but act within the news environment and ideas about what constitutes news. Facebook is based in California, and so most of the employees who make up the organization we call Facebook are American: they grew up within a specific media environment which had clear but subtle ideas about what news is. (As an aside, I wonder how many employees at Facebook who are involved in the curation of people's feed have any background in actual journalism.) To understand this framing of what is news and what isn't, we need to understand global history and the flow of information, a flow which often parallels economic flows. So yes, we need to understand words that some framings have determined should make us uneasy, such as imperialism and colonialism. (Think about it this way: in the Babar series of children's books, when Africans wear European clothes they are portrayed as good, but when there are Africans who wear non-European, "traditional", or "pre-contact" clothes [I am not sure what the best term is], they are portrayed as backwards -- yes, they are elephants and rhinoceroses, but they are being used as humans in the stories. This has not gone unnoticed.) Because often parts of the world that were used for colonialism and imperialism, empire building, and the extraction of goods through forced labor and violence, are now the parts that are not worthy of news coverage, although it isn't quite so easy and straightforward.
But what we do have is highly problematic, besides the sadly common lack of coverage in some parts of the world -- the Western news media didn't cover the Beirut attacks very much, neither did Facebook, and both of these non-reactions are for exactly the same reasons which can be couched in economic terms but have deeper cultural and historical roots. Facebook doesn't have as many users, most likely, who are directly connected to Beirut, but it has many more with connections to France. The same is true for their employees. But they are also reacting to what they see in the media and perhaps to trends they are continually monitoring, live, in the overall Facebook environment.
Like the media, Facebook is essentially bestowing the idea of newsworthiness on some issues and also deciding that some other things are not newsworthy at all. That really is a big problem, as it's clear no one there is qualified to do so. This is also a well-known issue more broadly and is not at all new. This is not to say it's good, it's not at all good, nor is it to say Facebook shouldn't have activated the "Safety Check" feature. I appreciated it, as I have friends in Paris.
There are also some technical issues, beyond deciding which events qualify.
For example, for an earthquake, what if I check in as "safe" after the initial earthquake, and then am killed shortly thereafter by an aftershock? (The same issue holds for other kinds of events, such as terrorist attacks.)
Facebook's page about the Safety Check says it's for natural disasters (as of November 15th, 2015), and does not mention other events such as terrorist attacks, nor how any of these will be selected. Yet it was used for an event that was not a natural disaster.

Facebook has taken action in a very contentious area, one where ideology and hegemony are heavily invested in outcomes and how we think about what is worth thinking about. Yes, as we should expect from most gigantic global companies, they did a bad job. As we know, people have been discussing these issues for a long time. These issues are still issues. Now, more people are talking. That's an important step. Steps are how we move forward.
Addendum: There is also the profile picture change to overlay the French flag on your profile photo, which again is not a bad idea, the problem is still which events are worthy of this level of attention, who is deciding, and how are these decisions made. It's the same problem as that with big data algorithms, except here it's with people's decision making.
Addendum, part 2: Here is an article from The Verge about why the people at Facebook who make these decisions did so, but I personally don't find the official explanation very satisfying about the criteria for their selection of events because the official response avoids all of the difficult issues that most people are talking about. If you're a company like Facebook, you can address these issues in a much better, direct, and clear manner.
Friday, October 30, 2015
The Civic Data Divide
I'd like to coin the term "civic data divide", and given that Google shows zero results for it, I think I can make that claim.
More importantly, I've been working on a paper looking at factors that affect the strength of a nation's open data policy. The numbers show that, although some people have theorized about the importance of both internet access and education for open civic data, neither of these factors play a role, at least not on the national level, indicating that, as we might expect, the early users of and agitators for open civic data are those who can use it: those who have internet access and those with the education to work with numbers. This is a minority of the citizenry, and as such the national measures for overall education and overall internet connectivity do not statistically relate to the strength of a nation's open data policy.
This should not come as a surprise, given the many other socio-economic divides in terms of access we've seen before, such as the digital divide. The civic data divide, I would argue, is an extension of what scholar Pippa Norris has discussed as the democratic divide, where there are some who use the internet to engage with governance and those who do not or cannot.
Yet this is not an overly problematic scenario. Internet access and education are indeed not evenly distributed across any one country, but many of those working with civic data and open data policies work every day with the issues faced by nations and cities, and as such they are aware of and engaged with socio-economic inequalities, and, more importantly, are trying to address the issues and make things better for all citizens. Along with the expansion of civic data programs and outreach (such as MIT's Civic Data Design Lab and NYU's Center for Urban Science and Progress), although the civic data divide currently exists, the very ideals behind open civic data are working to overcome it.
| Google as of October 30, 2015, 5pm NYC time. |
Edit: So, this does imply that those working on civic data are able to utilize their resources (socio-economic) for education so they have data skills, and so they can do this outside of their nation's educational system. But besides those that already have the resources for education, I'm guessing there are some who instead learn the needed skills via online courses, meetups, and other alternative educational avenues. But you still have to have the time to work on these projects.
Tuesday, October 27, 2015
Blue Background, White Text
Microsoft Word used to have a fantastic option, making the background blue (instead of white) and the text white (instead of black). I and many people liked the change of contrast. I first remember falling in love with this feature in the much-loved Word 5.1 a long, long time ago (circa 1992).
I use it on my home machine with Word 2011. But with my new laptop, Word 2011 was not an option, I had to use Word 2016, which I rather like so far (despite initially causing massive problems for my citation management software). And, the option for blue background, white text is gone. And that's disappointing and problematic.
Having most of the screen be white (the background) makes the screen very bright. It's like staring into a light, albeit a dim one. You want to keep the contrast between the text and the background, but you don't need black on white to do that. A lot of interfaces do that and I think it is stupid. Even this Blogger editor is doing that (but notice what I've chosen for my blog layout). This is a blog, it isn't ink on paper, it's way beyond that.
Which is another part of the issue: the paradigm. This is a computer, it's not ink on paper, which is a whole other technology. Yes, writing papers on the computer stems from typing in black ink on white paper on a typewriter, but this isn't a typewriter. You can change the writing in your document to two columns, add images, add footnotes, move anything anywhere, add page numbers, make sections, change something to italics after you write it, have hyperlinks.... You know. Computer word processing is based on typing on a typewriter, but it is light years beyond even an IBM Selectrix II with correctable ribbon. The computer can spellcheck. You can edit on the page and it will shuffle the text around. You can justify the text after you type it and change all the margins, then undo and redo all of that. You can repaginate on the fly (they actually just do this these days). I could list probably hundreds of ways in which a word processor is different from the black ink on white paper typewriter experience. You can change the typeface and font size after you have typed the words--try that on a typewriter. Yet, the product managers for Word at Microsoft have decided that this is the right way, and the only way, to do it. It's an outdated paradigm, and it sucks for my eyes.
Feature creep is one thing. Removing a useful feature that's been around for over 20 years is another.
And I loved the file icon:

AoIR 2015
Just spent a few days at AoIR 2015 in Phoenix! Note the hilarious typo ("indipendent") and we were not sure how that happened (it was discussed).

Thursday, October 15, 2015
More Borderlands 2 Homage
Two more examples to go with the previous post, although ones I ran into, not from Twitter.
The first one is from the movie Top Gun, referencing the Kenny Loggins song "Danger Zone", which is hilarious, in this quest, and the name of the quest is also a line from the film.

The second is from the amazing kids' book that you should all read, The Phantom Tollbooth.
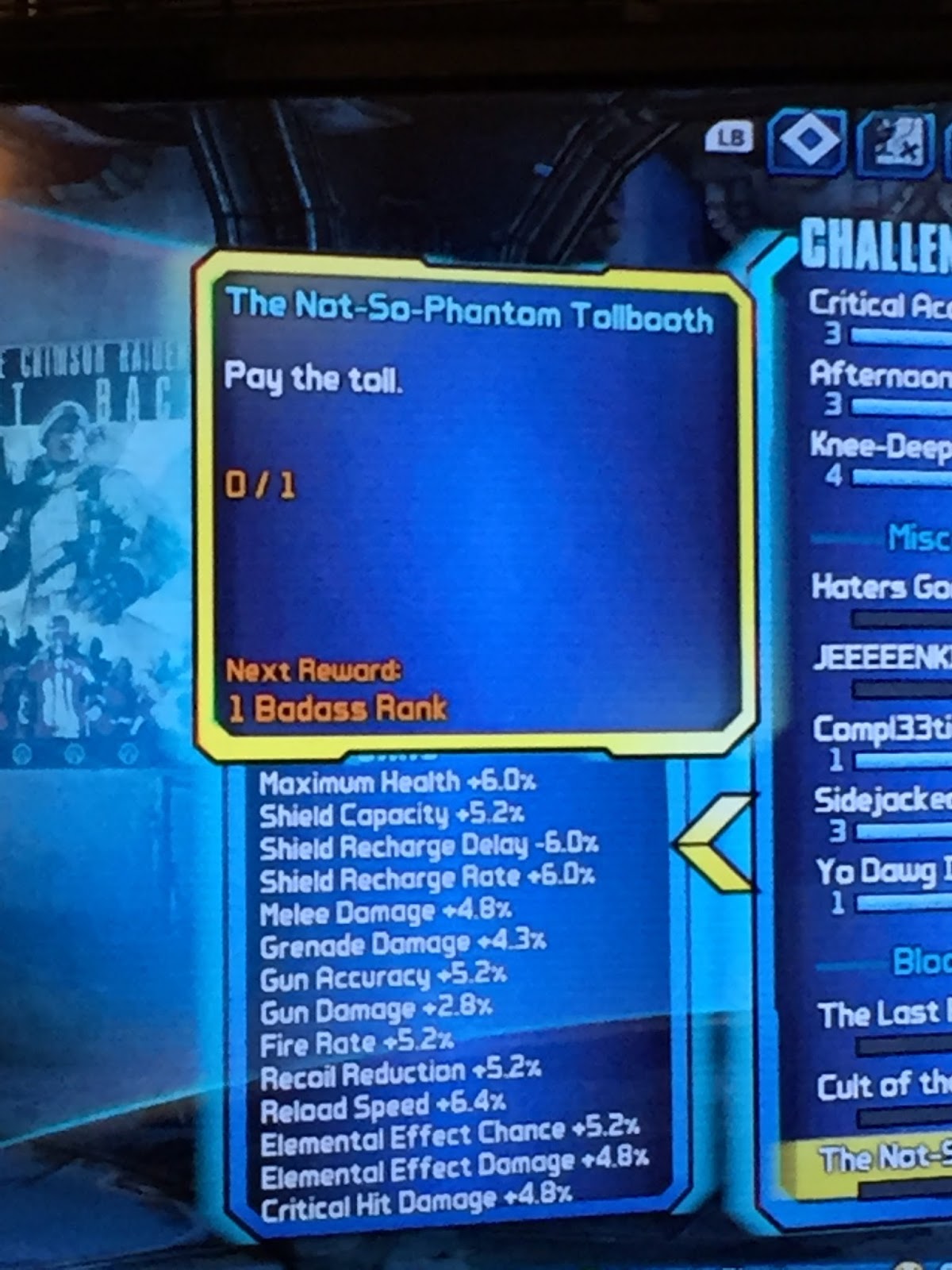
Wednesday, October 7, 2015
More In-Game Homage
I have written, not at all exhaustively but somewhat extensively about in-game homages before, including one example from Borderlands 2. But I was in Twitter and ran into some Borderlands tweets about their in-game homage, although they referred to them as "Easter eggs" which isn't exactly how I would contextualize it. I like the topic, and the two examples they had, so present them here.
Homage is a great thing, and we love to play with the things we love, so there is cultural play, and being in the know about things also makes us feel special, or clues people in to what they should know if they don't so they can be in-group. In-game homage about other games is fantastic, but interesting given intellectual property laws.
The first, and if you're a gamer you won't need these explained, is homage to Donkey Kong, an early Nintendo game I played in junior high in about 1983 in the back of Sage's Jr around the corner from my school, and where you played as now-famous Mario. "Donkey Mong" is holding a barrel above his head, about to throw it, just like Donkey Kong.

This one refers to a current favorite, Minecraft, both via the blockhead appearance and part of the text refers directly to Minecraft (this could be an approved homage for all I know, it's unusually direct in the text and most homages aren't, they change something small like Donkey Mong for Donkey Kong).

Friday, October 2, 2015
Fixing Gephi on Your Mac
TL;DR: Download JDK 1.6, then point a Gephi startup file to it maybe with one change (/Library... and not /System/Library...).
UPDATE: New Gephi is out!
Original post continues below.
The longer version is that Gephi, which I love, hasn't had an update (as of this writing) in quite some time (parts of it have, parts haven't) and it doesn't work with the newer versions of Java. The 0.9 version download file for OS X doesn't seem to be where the link says it should be (again, as of this writing in early October, 2015).
Apparently Gephi 0.8 needs Java version 6, not version 7 or 8. Java appears to have lots of parts, names, and maybe even v6 is "1.6" and v7 is "1.7" which I don't understand but I don't do Java so I'm not going to spend time figuring it out--I got Gephi to work, that was all I cared about right now.
My new laptop, to replace my five-year old one, didn't even have Java on it (ah, the purity of it all). I got the JDK (Java Developer's Kit) 1.6 from part of the Apple Support website, which is what you want.
But you have to tell Gephi about it, as far as I know. This article was awesome except it turned out on my machine not quite right (but close enough that I figured it out). Java wasn't where I thought it would be. This article on Stackoverflow helped me find Java 1.6, although note the article is about Java 1.7, so make the command this:
/usr/libexec/java_home -v 1.6
(Ok now you don't need to read the Stackoverflow page, just run that in your terminal if you've installed 1.6 and don't know where it is.)
Turns out, I don't know why (and I don't care, it's working) Java 1.6 wasn't in /System/Library... it was instead in the same path but not the one in /System, it was just in /Library....
/Library/Java/JavaVirtualMachines/1.6.0.jdk/Contents/Home
So, put that line in the Gephi startup file near the top as per the directions (I made it the first command) and so far Gephi actually loads, which it wasn't doing before. Granted I haven't actually tried to do anything with it, and who knows if this will blow up other Java things (or maybe my machine really didn't have any Java on it at all).
Monday, August 31, 2015
Python, DictReader, DictWriter
Because I can never, ever, remember exactly how to code these. Example of both, basic.
data_list = []
with open(input_file, 'rU') as f:
data_file = csv.DictReader(f)
for line in data_file:
data_list.append(line) # gets you a list of dicts
the_header = ['h1', 'h2', 'etc'] # column headers, a list of text strings
with open(output_file, 'w') as f:
file_writer = csv.DictWriter(f, fieldnames=the_header)
file_writer.writeheader()
for line in data_list:
file_writer.writerow(line)
Here I am going to experiment linking it as a script-tagged element from Gist via GitHub:16th Century Maps for 21st Century Data Science
Maps bother me. I love them, and I'm not a geospatial GIS coding specialist, but I do visualizations, and we keep using the wrong maps. Greenland is a lot smaller than all of Africa, ok?
This is the map in my office kitchen:

It's the typical Mercator projection (projection, since you have to "project" a sphere onto a flat surface, which doesn't work well). Mercator came up with this map view in 1569, according to Wikipedia. Yet we still use it for 21st century data science! Granted just because something is old doesn't mean it's not useful, but in this case the Mercator projection was created primarily for navigation, that is, sailing the seven seas. When you present geospatial data the only thing your viewers are navigating is your data. As such this is totally the wrong mapping projection to use. Totally. Don't do it. Data visualizations are about accuracy, and using the Mercator projection starts you off with a completely inaccurate mapping. Greenland and Africa? "Africa's area is 14 times greater" than Greenland according to that Wikipedia article! Fourteen!
So what to do instead?
Wikipedia has a page of many different projections, I'd vote for one of the equal-area ones, and am a fan of the Gall-Peters projection (which was the centerpiece of a great segment on The West Wing), but you'll need to decide what's best for your use.
So, I'm a little upset about the giant Mercator map in my office, but with good reason.
Sunday, August 2, 2015
Code for All Summit
Had a great time at the Code for All summit, held here at Civic Hall. Global meets local with a variety of civic tech people and a few government and NGO people thrown in. Code for All is the global offshoot of Code for America.
One nice thing to see was that yes, sometimes the best solution is SMS and not a fancy app.
That's me in the front row second from the left.

Monday, July 13, 2015
Music in an MMO!
Oh this is exciting, but I don't play each and every MMO (that would be insane) so didn't know about it.
Cheng, W. (2012). Role-Playing toward a Virtual Musical Democracy in The Lord of the Rings Online. Ethnomusicology, 56(1), 31-62.
There's no abstract, but here's an early paragraph:
In an attempt to honor the rich musical lore of Tolkien’s Middle-earth, Turbine implemented in LOTRO one of the most elaborate player-music systems in any MMORPG to date. This system allows a player to perform both live and pre-recorded tunes that can be heard by other nearby players in the gameworld. A player’s musical performance is visually simulated by avataric motions and strings of colorful notes that float out of a character’s equipped instrument (see Figure 2). Examples of such instruments—each of which sports a different synthesized timbre and a range of three chromatic octaves along the Western twelve-tone scale—include the bagpipes, clarinet, flute, horn, cowbell, drums, harp, lute, and theorbo.The wiki page seems pretty informative, and there's a website repository for the ABC music notation files.
I love it when people make things and share things, and music is community-based, a form of communication, and is very old! The oldest instrument we've found, a bone flute, is about 40,000 years old and it certainly wasn't the first musical instrument, since flutes aren't that easy to make.
Sunday, June 14, 2015
Python, OSX, and Computer Name
Sounds thrilling! No not host name, but the name you give your computer -- so my multi-core beast is "NeXTcyl" (like a NeXT cube but a cylinder).
It was somewhat difficult to find, well, not the best way to do this in Python, but the only way I could find to do it in Python for OSX. Lots and lots of method for hostname: no no no Google, not that. You want to call out to scutil, a command line program.
import subprocess
this_computer = subprocess.check_output(["scutil", "--get", "ComputerName"])
Essentially, use the subprocess library to call a command line function, use the check_output component to get the output from it (important!), and the three parts of the command line command are all cut up into the different arguments you hand the call (also important!). I tried about four other approaches before this one, and then had to try about three different syntaxes to get it to work, since I couldn't find any good online help. Here you go. For OSX, not Windows or other *nixes. No idea what they will do (nothing bad, but maybe not what you want).
(Because I have a 3.6 GB file I don't want to put in DropBox, so I have a local copy on my desktop and on my laptop, but the files are in different paths on each, so I wanted a way to detect which machine the code was running on so as to call the right file path -- I could have just tried one path and if it failed use the other, but, I only just thought of that now.)
Monday, June 1, 2015
400,000 Years Ago
400,000 years -- we're only at 2,015 in the "common era". So roughly 398,000 BCE. The Great Pyramid of Giza is from around 2,560 BCE, and Stonehenge is from between 3,000 BCE and 2,000 BCE. The cave paintings at Lascaux are from approximately 15,000 BCE. The earliest musical instruments found, bone flutes (bone survives well in the archaeological record), are about 35,000 years old, that is, from 33,000 BCE (although there is some disagreement about some finds and dates).
200,000 years ago is when we think the first humans -- homo sapiens -- evolved.
400,000 years ago is when homo heidelbergensis, not us but our ancestors, existed. No humans.
And this is a chipped (napped) stone instrument they made, possibly to cut animals apart. And that's me holding it at the British Museum. HOW COOL IS THAT I'LL TELL YOU IT'S VERY COOL.

Ex Machina and Chappie
Contains spoilers, totally and completely. I mean, it's the internet.
I caught both recently on Virgin Atlantic. The screen was a little small and glossy so had lots of reflections, which did not do well by Ex Machina but Chappie does fine with it. (I think a better title for Chappie would have been Scout 22, since "chappie" makes little sense in American English.)
Both, by the way, are recent movies about AI, yet they are very different.
Ex Machina has a few characters, few speaking parts, and is sparsely beautiful (best watched on a big hi-def screen).
Chappie has lots of speaking parts, and is familiar to viewers of Blomkamp's film District 9 in terms of the visuals -- a rough, decaying world in South Africa with lots of little details, because when things fall apart or get blown up there are lots of little bits.
In this, they are opposites. They are also opposites in how they treat AI -- in Ex Machina, the AI is software and hardware (the cool glassy blue brain objects), and the objective is humanity -- they have human faces, bodies, and can make and read human facial expressions. In Chappie, the AI is in a somewhat clunky-looking (but adroit) robot body, and the AI is the software (it can survive in a USB dongle).
For Ex Machina, the point is for the AI (and its body) to become human.
In Chappie, human consciousness can be scanned and downloaded into the robots (no special brain neeeded, although the robots have good brains -- this is science fiction, after all).
So AI/robots becoming human, and humans becoming robots.
Yet they share the same approach to the creator, a male genius who is the solo creator, more or less of a loner (it varies in the two films).
In Ex Machina, the AI/robot seeks to hide in humanity and does not trust them (well not the initial human characters) and kills her creator (although the creator is horribly abusive and ego-maniacal), whereas in Chappie, we know they become known more widely to humanity and Chappie (the AI in the film) trusts the humans he comes to know and helps save one of them, the AI creator.
Ok I don't really have anything deep to say, but they are both pretty good. In Ex Machina I think the two main male characters aren't written as well as they should be, they are a little overdone and tedious at times, but in Chappie I really liked the characters, and Die Atwoord are great. Ex Machina would have benefitted from a better, bigger screen. I also thought the music in Chappie was really good. I also thought Alicia Vikander's performance was great as the main AI in Ex Machina.
Apparently I disagree with reviewers on all this.
Lost Things
From the amazing British Museum, here is a 4-5 foot tall staff that apparently humanity just lost track of despite it being perhaps one thousand years old (or at least 700 years old). "Oh that old thing?"
"It was found behind a London solicitor's cupboard in 1850..." BEHIND A CUPBOARD.


ICWSM 2015

Had a great time at ICWSM in Oxford last week. Great people, great place. Stayed in a hotel near the old Norman tower mound that was built in 1071. (Google's formatting is horrible with images and text, I am discovering.)
We discussed a wide range of data and social science topics, including data availability.
 |
| Original Image c/o Allie Brosch |
Darren Stevenson, PhD student from my old department, Communication Studies at UM, presents!

|
My poster! 36 million observations!


Friday, May 22, 2015
Google #datafail
I keep getting ads in my Gmail (web interface) for Masters' programs or programs in education.
Are you kidding me?
Google reads all my email, this blog is in a Google property, I have a Google Scholar page so they should know I have a PhD, really, and I have a Google Sites page.
Serving me ads like this makes no sense at all. None. No, really, it doesn't. It's indefensible. But yet, they do it.

Wednesday, May 13, 2015
WUN Understanding Global Digital Cultures Conference
I was recently at the WUN Understanding Global Digital Cultures Conference, at the Chinese University of Hong Kong -- I just haven't posted about it since the jetlag is terrible!
There were some great papers, some great people, and some great ideas. Although I've been to Hong Kong before, I hadn't previously been up in the New Territories, and that area was great to see although we didn't tour around too much.
So not only did the esteemed and recently tenured Dr. Roei Davidson and I present some groundbreaking work we've done looking at crowdfunding and Kickstarter, but we also got tweeted by the director of Pew Research Center's internet, science and technology, Lee Rainie, which was awesome -- he is one of the best tweeters I know and he's older than I am! So much for youth being the digital natives. Here's one of his tweets (he had a few!). (Good publicity from a smart source!)

Jetlag fighter!

That's me in the lower right.
Monday, April 20, 2015
I am not a number!
I was poking around the web after the TtW conference and found this blog post rather apt.
And then this excerpt from Joe Turow's The Daily You aligns well with it.
Friday, April 17, 2015
Theorizing the Web 2015
Theorizing the Web 2015 is on! Here in the Bowery (LES?), two days of presentations. Already made some contacts about work and am looking forward to tomorrow when some people I know will be keynoting!
Ignite Talks at Civic Hall: Great Stuff!
Omidyar Network hosted a great bunch of ignite talks (the crazy auto-slide-advancing ones) at Civic Hall on April 13th, including a few people I know which was exciting!

The Speakers:
- Laurenellen McCann Mo Open Data
- Tony Schloss Red Hook WIFI- The Realest Community Tech
- Miriam Altman The uphill battle to graduation day
- Chris Whong In Search of Hess' Triangle
- Rose Broome What is the Basic Income?
- Lane Becker Good Enough for Government Work?
- David Riordan The NYC Space/Time Directory: How The New York Public Library is unlocking NYC's past
- Gavin Weale SA Elections 2014: a youth odyssey
- Paul Lenz The Resilience of the Past
- Kathryn Peters Disrupting government
- Joel Mahoney Civic Technology and the Calculus of the Common Good
- Kate Krontiris Understanding America's Interested Bystander
- Nick Doiron The Civic Deep Web
- Jessie Braden Open Data Perils: Question Everything
- Daniel X. O'Neil Changing Civic Tech Culture from Projects to Products
- Daniel Latorre What I Learned About CivicTech from Eastern Europe
- Noel Hidalgo Clear eyes. Full heart. Can't Loose! NYC's civic tech in 2022.
Great topics, some great ideas, and some great slides.

Monday, April 13, 2015

Friday, April 10, 2015
SQLite and Python Notes
I don't have a background in SQL, so getting the syntax correct for SQLite in Python was a little tricky, especially since it reads like it's straight out of 1983. So, here is some working syntax for a search/select and replace, and also a search/select and an iteration through the results.
Search for one result (on a unique variable) and change some of that entry's data:
cursor.execute("UPDATE outfits SET size=?, members=?, scraped=? WHERE id=?", (how_many_members, char_id_list, 1, int(outfit_id)))
db.commit()
This assumes you know a bit about SQL. cursor is your cursor object. This snippet searches the db for any entries (lines, rows, whatever) for where the id variable matches the value of outfit_id. In this case, that variable will have all unique entries since I declared it that way when I made the db (which is some other SQLite code that is in multiple other places on the net). So, this line finds the one I want and then changes those three variables, then you commit it which actually write it. That seems really weird to me, either do it or don't do it. I assume this made some sense back in 1983 when people wrote code in capital letters.
Oh and outfits here is the name of your table in the db. Well it's the name of
Iterator on search results:
cursor.execute("SELECT * FROM outfits WHERE scraped=?", (0,)) # this selects them but doesn't return them for use. NOTE TUPLE!!!
not_scraped_outfits = cursor.fetchall() # aha!
for an_outfit_row in not_scraped_outfits:
# do your stuff here
That seems weird to me, but I guess I don't understand the cursor idea. You SELECT in caps, but then you have to fetchall(). That seems like two steps where you only need one. So, you SELECT everything (the asterisk, I think) from your table that matches the WHERE call, here where scraped is 0, since it's a Boolean. That returns possibly none, one, or more. Usually for me in this particular code it will return several, and then you have to iterate through the results, and I think there are a few ways to code the iterator call, but the code I have here works so there you go.
Execute a SELECT which is a search (the WHERE), then fetchall the results (even though you already selected them), then you can iterate through them.
NB: Tuple! When you do the funky security thing, which I can't explain and don't care about since I am only running local code, the argument has to be a tuple, so if you are just passing one argument you need a trailing comma:
cursor.execute("SELECT * FROM outfits WHERE scraped=?", (0)) # fail
cursor.execute("SELECT * FROM outfits WHERE scraped=?", (0,)) # success, due to the last comma there
More also, it is apparently a good idea to store really long ID numbers as text, not numeric. (Because something, somewhere, decided to round them all off so they were all wrong.)
Thursday, April 9, 2015
Kickstarter Talks
A great evening at Kickstarter HQ here in Greenpoint! Three fantastic talks about processes they use there:
- Kumquat: Rendering Graphs and Data from R into Rails, by Fred Benenson, Head of Data.
- Rack::Attack: Protect your app with this one weird gem! by Aaron Suggs, Engineering Lead.
- Testing Is Fun Again, by Rebecca Sliter, Engineer.
It is always great to see uses of ggplot, especially on data upon which I also use ggplot, and I got to talk to Aaron about the throttling they do to stop malicious scrapers (I fall into the non-malicious camp of course!).


Here is Aaron talking about throttling overly requesty processes, which I found really funny since I have scraped Kickstarter but hopefully for good not for evil.
Finally, here is a ggplot chart I made of some Kickstarter data, for Music, US projects, with various other long-winded details, but this shows that, out of those who succeeded on their first project (blue line), people with a lower pledged/funder ratio (left side) were slightly more likely to do a second project (higher on the Y axis) than those with a higher pledged/funder ratio. We call this ratio "the sugar daddy" measure, since if you are higher on this measure, maybe your rich uncle came in at the last minute to save your project.

Friday, April 3, 2015
R and Unlist Your List!
If you try to assign a list to a column in an R data frame, it won't quite work, you need unlist. (That's the short version for the search engine snippet, although it does not make for a great narrative intro, it's more the concise summary.)
A few days ago, I was working in R, and was generating a new data frame from another one. It was a little more complex than I was used to, for instance I had to bin one variable by the values of another variable, and make some new percentage/frequencies in the new, smaller, data frame, so I couldn't just use the non-looping approach that is common to R (and which is a lot nicer and fast). The data frame was relatively small, so one loop level was not a problem, even on my 4.5 year old MacBook Air.
In one section, I generated a list of values (numeric, nothing fancy), and then assigned that list to a column in my new data frame. When I called the data frame to look at it, it looked fine, but if I did str(my_df) or summary(my_df) something was horribly wrong -- the column wasn't a numeric column, it was some odd list format and wasn't working for my ggplot.
I tried assigning the generated values directly to the column in the data frame, with something like this inside the loop, where I also incremented i:
my_df[i, 'the_variable'] = one_generated_variable
(Note I can't use R syntax there with the greater than sign, Google barfs on the code even though it's text, so I have to use the equals sign which is older R style.)
one_generated_variable was just a numeric value. Should have been fine, I thought! But no, it still came out as a list. I have no idea why, honestly it seems impossible since the values were generated one at a time and assigned then and there -- they were not bundled into a list first. But, unlist fixed the problem.
my_df$the_variable = unlist(my_df$the_variable)
That did it. I still don't understand the details, since I don't see why it was a list in the first place (aren't columns vectors anyways?). I have never run into that problem before, although mostly I've been working in Python lately.
Also, a friend put me onto data.table instead of data.frame for bigger data.
Saturday, March 21, 2015
CSCW 2015 Vancouver
Just got back from CSCW 2015, what an awesome conference. Great people and great papers. I am rather dismayed I have not been before!
Thursday, February 19, 2015
Nice Little Python Trick
I can't summarize this for a headline, but I have a list (CSV) of KickStarter data, where each line is a project and includes the project URL and founder KickStarter username. I wanted to go in and get the biographies for each founder who had more than two projects. First I needed to drop all the one- and two-project people (easy), but then I'd have multiple URLs for each remaining founder. So, for someone with three projects, I'd have three unique URLs but only needed one.
I imagined sorting, or splitting, or checking against founder names that were already accounted for. Horrible. Then I realized... Dictionaries! With founder as the key.
So I read the CSV as a list of dicts (typically how it is done, but so few examples show this online it is horrid), so had
data_list[i]['founder']and
data_list[i]['proj_url']to work with.
And now Google insists on line breaks there with the pre tag. Sigh.
But, the solution! Since I only needed one URL per founder, it didn't matter which one I had. So I could just loop through the data once, and grab every URL, and let the dict just overwrite founder-key entries with any URL for that founder. So, the following code only loops once, returns a nice dict object, and uses founder names as the keys.
url_dict = dict()
for project in data_list:
url_dict[project['founder']] = project['proj_url']
So for someone with, say, three projects, it will assign the first URL to their username, then assign the second URL and overwrite the first URL, and then the same for the third URL, overwriting the second. So I end up with every username associated with one appropriate URL. Perfect. No sorting, no checking, no nothing. Automatic, essentially.
So I thought that was nice.
Sunday, January 25, 2015
Random R Notes - Factors, Rank v. Order, Unsplit
Some R issues I have run into recently...
I split a dataframe, then split it again, and the analysis was taking forever. Something was wrong. After inspection, the sub-split DF had all the factor levels from the original DF! Terrible since there were about 25,000 in one variable. It just took forever, which I don't think it should but hey I gave up on it.
I needed droplevels. You can apply it to the whole DF, removing unused levels from your old DF and then assign it (to a new one or just write over the old one).
your_new_df = droplevels(your_old_df)
(Google cannot handle the less than sign, used for "get" in R instead of =, with either the code tag or the pre tag, it just blows it up. Annoying.)
Then I could run the ordering code on dates. But no: there is, I learned, order and there is rank. There is also sort but I managed to avoid that somehow, so I won't discuss that here.
Note that for rank you need to figure out what to do with ties! (That is, when values are equal, how to rank them exactly.)
There was a really great post about it on Stackoverflow but I can't find it at the moment. This post might help, though.
Or, I made a nice little example! I use R: as the start of the input lines since the greater than symbol and blogger are not friends.
R: the_list = c('A', 'D', 'B', 'C')
R: order(the_list)
[1] 1 3 4 2
R: rank(the_list)
[1] 1 4 2 3
So, you see the two outputs are different.
Order says, put the first element first, then the third element would come next (B), then the fourth element (C), then the second element (D).
Rank says, the first element is first, the second element (D) is the fourth of them all, the third element (B) is the second overall, and the fourth element (C) is the third overall.
Edit: I called sort!
R: sort(the_list)
[1] "A" "B" "C" "D"
So after that, I wanted to unsplit. But, no, I had added the rank column, so instead of 400 rows I only got 100 (I had 100 df's with 4 rows each). Unsplit does not work well (or at all?) if you add (or subtract?) items. So stackoverflow told me I needed do.call and rbind ("row bind").
rejoined_df = do.call(rbind, splitted_df)
Note that the splitted_df is the result of the split() call, which I'm not showing, so is not actually a DF, I think it's a list of DFs maybe. Or maybe it's not a typical DF. But you can call it directly, and if you use split you should familiarize yourself a bit with the resulting object.
There you have it, some random R notes.
Tuesday, January 20, 2015
Apple's Audio Outputs and #Fail
If you want to stream sound on your Mac to your stereo jack speakers by the computer and to your Apple Airport Express with its audio, you can't if your sound stream isn't through iTunes and is, say, via the web (like with Pandora in my case). Not at the same time, regardless of what the web says. The stereo jack output doesn't work that way, apparently. (This does work quite well if your sound source is iTunes, note.)
A lot of sites say you can do this generally, and have detailed explanations about how you make a new device through the Audio Midi Setup app. An article at MacWorld hints at the problem but isn't at all clear: "Let’s say you have an Airplay device plus a USB, ethernet, or Firewire audio interface attached to your Mac..." Right. Note the article doesn't mention the stereo out port (the one that matches your little headphones on your iPhone, Android, or oldschool Walkman), because it won't work.
The best I got was stereo on my Mac and one horribly noisy speaker on the Airport Express (through a receiver). The easy solution, although I haven't actually tried it, is to use one of the other sound outs on the Mac (probably the monitor over Firewire) instead of the speakers, but I like my speakers here. The other, better and more expensive solution, is to go with Sonos -- a friend of mine has some Sonos devices and it is an awesome setup, very easy to use and understand, streams from lots of sources, and the app on the iPhone seems great to me.
Update: You can make an "aggregate" device or a "multi-output" device, and neither works for me at all. When I tried using the Airport and the Firewire monitor speakers, which seemed like it should work via all the online help, it didn't -- the best I got was one of the two speakers on the receiver via the Airport (both of which work fine through iTunes or System Preferences when the Airport is the only sound out device) and the monitor speakers had a large amount of noise (a hiss, to be specific). This is unbelievable. Apple is usually really good about making simple things easy, but not here. Weird given how great NeXT hardware and software were at sound.
Update 2: I FOUND A SOLUTION! Via TidBITS, the little app Airfoil from Rogue Amoeba! It works! And it's only $29.00 as I am typing. Really OSX should just do this, but it doesn't, and $29 for a solution that does a lot more than what I am trying to do currently (that is, it gives me future flexibility) is great.
Thursday, January 8, 2015
Amazon's Data Fail
So, I believe I have been an Amazon customer for well over ten years -- at least eight since I moved here to NYC, and I ordered stuff from them prior to that.
However, Amazon continues to ask me if I want the college student discount almost every time I check out. This is absurd. And there is no way to toggle it off, I had to get customer support in chat and not even he could do it, he had to bump it up to his supervisor.
Given all the data Amazon has on me, they should know better. It's not just a question of an algorithm, someone -- a team most likely -- was in charge of the implementation here, not just of the algorithm but of the page and its features.
They have the data, and the feature knowledge, yet they failed tremendously anyways. This is not the "Target knew a woman was pregnant before her parents did!" story.
Here is the actual screenshot I took, this is not some random illustrative image I grabbed from somewhere else on the web:

Subscribe to:
Posts (Atom)